——呂天文
一、大數據市場規模與特征分析
大數據產業是指對互聯網、移動互聯網、運營商等渠道產生的大量數據資源進行快速獲取、收集存儲、價值提煉、智能處理和分發,從而用于企業決策支持等方面的信息服務業。
大數據全生命周期可以劃分為”數據產生--數據采集--數據傳輸--數據存儲--數據處理--數據分析--數據發布、展示和應用--產生新數據”等階段。因此,大數據產業鏈主要包括數據源層、數據存儲平臺層、數據分析和挖掘層以及大數據應用層。大數據應用層主要分布在互聯網、電信、金融、零售和政府等行業,和企業用戶的業務更加結合得緊密,通過大數據分析實現商業智能(BI)、決策支持和用戶需求挖掘等應用價值。

圖1 大數據產業鏈分析
數據來源: ICTresearch
由于中國互聯網業務規模和移動終端數量的快速增長,業務數據和交互信息的爆炸式增長,中國大數據應用開始進入發展元年,應用市場規模增長提速。根據ICTresearch的研究顯示,2012年,中國大數據應用市場規模為4.5億元,同比增長40.6%。
表1 2010-2012年中國大數據應用市場規模與增長

數據來源: ICTresearch
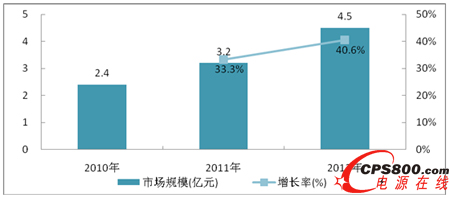
圖2 2010-2012年中國大數據應用市場規模與增長
數據來源: ICTresearch
二、當前大數據相關政策分析
大數據是一個具有國家戰略意義的新興產業,正受到政府的高度關注。2012年5月,國務院頒發了《”十二五”國家戰略性新興產業發展規劃》,提出高端軟件和新興信息服務產業發展目標:加強以網絡化操作系統、海量數據處理軟件等為代表的基礎軟件、云計算軟件、工業軟件、智能終端軟件、信息安全軟件等關鍵軟件的開發,推動大型信息資源庫建設,積極培育云計算服務、電子商務服務等新興服務業態,促進信息系統集成服務向產業鏈前后端延伸,推進網絡信息服務體系變革轉型和信息服務的普及,利用信息技術發展數字內容產業,提升文化創意產業,促進信息化與工業化的深度融合。在關鍵技術開發方面,開展移動智能終端軟件、網絡化計算平臺與支撐軟件、智能海量數據處理相關軟件研發和產業化。
2012年2月,工信部發布《物聯網”十二五”發展規劃》,把“加強處理技術研究”作為核心技術攻關之一,提出:重點支持適用于物聯網的海量信息存儲和處理,以及數據挖掘、圖像視頻智能分析等技術的研究,支持數據庫、系統軟件、中間件等技術的開發,推動軟硬件操作界面基礎軟件的研究。將“信息處理技術”列為四項關鍵技術創新工程之一,包括海量數據存儲、數據挖掘、圖像視頻智能分析。另外三項關鍵技術創新工程,包括信息感知技術、信息傳輸技術、信息安全技術,也是大數據產業的重要組成部分,與大數據產業發展密切相關。
2013年,國務院發布《關于推進物聯網有序健康發展的指導意見》,提出加快傳感器網絡、智能終端、大數據處理、智能分析、服務集成等關鍵技術研發創新,推進物聯網與新一代移動通信、云計算、下一代互聯網、衛星通信等技術的融合發展。重視信息資源的智能分析和綜合利用,避免重數據采集、輕數據處理和綜合應用。
自2012年,國家已經陸續出臺了與大數據應用相關的產業規劃和政策,從不同側面在推動大數據產業的發展。然而,專門針對大數據發展尤其是基于互聯網應用的社交大數據的政策規劃還沒有。為了充分利用大數據的價值,中國大數據產業的發展需要上升到國家戰略層面,特別需要從政策制定、資源投入、人才培養等方面給予強有力的支持。企業與相關的新興產業和行業結合,通過相關產業的政策帶動大數據產業的發展;另一方面是在國家政策的引導下,成立聯盟、建立專業組織,引導大數據政策提出和產業環境的建立。
三、當前主要技術發展趨勢分析
在目前大數據發展背景下,數據存儲技術、處理技術、分析技術等在不斷創新和完善,開放的技術平臺和系統的發展主要呈現以下幾方面的趨勢:
(1) 大數據的去冗降噪技術
大數據一般都來自多個不同的源頭,而且往往以動態數據流的形式產生。因此,大數據中常常包含有不同形態的噪聲數據。另外,數據采樣算法缺陷與設備故障也可能會導致大數據的噪聲。大數據的冗余則通常來自兩個方面:一方面,大數據的多源性導致了不同源頭的數據中存在有相同的數據,從而造成數據的絕對冗余;另一方面,就具體的應用需求而言,大數據可能會提供超量特別是超精度的數據,這又形成數據的相對冗余。降低噪聲、消除冗余是提高數據質量、降低數據存儲成本的基礎。
(2) 大數據的新型表示方法
目前,表示數據的方法不一定能直觀地展現出大數據本身的意義。要想有效利用數據并挖掘其中的信息或知識,必須找到最合適的數據表示方法。數據表示方法和最初的數據產生者有著密切關系。如果原始數據有必要的標識,就會大大減輕事后數據識別和分類的困難。但標識數據會給用戶增添麻煩,往往得不到用戶認可。研究既有效又簡易的數據表示方法是處理網絡大數據必須解決的技術難題之一。
(3) 高效率低成本的大數據存儲
大數據的存儲方式不僅影響其后的數據分析處理效率也影響數據存儲的成本。因此,需要研究多源多模態數據高質量獲取與整合的理論和技術、流式數據的高速索引創建與存儲、錯誤自動檢測與修復的理論和技術、低質量數據上的近似計算的理論和算法等,實現高效率低成本的數據存儲方式。
(4) 非結構化和半結構化數據的高效處理
目前,非結構化和半結構化數據在整個大數據中占有相當大的比重,而關系數據庫系統的出發點是追求高度的數據一致性和容錯性,因此,傳統的關系數據庫技術無法勝任這些數據的處理。系統的高擴展性是大數據分析最重要的需求,必須尋找高擴展性的數據分析技術。以MapReduce 和Hadoop為代表的非關系數據分析技術,以其適合非結構數據處理、大規模并行處理、簡單易用等突出優勢,在互聯網信息搜索和其他大數據分析領域取得了重大進展,已成為大數據分析的主流技術。然而,MapReduce 和Hadoop 在應用性能等方面還存在不少問題,還需要研究開發更有效、更實用的大數據分析和管理技術來適應大數據分析方面的技術需求。

- 1
- 2
- 3
- 總3頁
http:www.mangadaku.com/news/2014-3/201432184226.html


